
The Client is attempting to build a social media platform tailored towards solving a very niche area of the digital market, for which a lot of specialized learning and implementation is necessary. As a halo project, a recommender system is being implemented to customize and tailor content to the users of the social media platform. A lot of advancements are being made with parallelization with GPUs, scaling across different nodes, as well as the highlight feature in the pipeline: localizing compute and making use of the compute power of the edge device to run code to remove the compute complexity scaling problem altogether.
The Client aims to make a newsletter-style carousel of productive articles for their Employees, for which a solution was built that scours the internet, finds good blog articles over 16 different categories, and renders them into friendly email blasts that can be circulated company-wide.
Goal and Summary: To meet the ever-increasing demand to store multimedia more efficiently with no perceivable loss in quality from the Client, a solution was developed to smartly manage, compress and store multimedia content being uploaded to their servers. This code was imperative to be realtime in nature, so as to facilitate minimal perceived lag on the Client’s end, as this use-case is very read-heavy. Acceleration with Nvidia GPUs was obtained and successfully implemented, with a final compression ratio (in terms of filesize) of about 22.4:1 with no perceivable lag and loss in color information. Data Collected and Processed: A projection chart of the estimated storage needs pre-optimisation, as well as a specification list with respect to the desired quality of the images and media post compression. Additionally, a thorough investigation was also conducted on the feasibility of the status-quo installation, with research about the media type breakup, typical sizes and read frequency of these files. Methodology: A number of Python-based libraries concerning media processing were investigated, including, but not limited to moviepy and ffmpeg. Once the prototype had been established, the engine was augmented with pandas capabilities to automate the reading of the data influx, as well as the management of the files. Once this was established in the first phase of the project, a further optimization requirement in terms of compute complexity and costs were identified, and to accelerate the code, moving it away from CPU compute towards GPGPU tasks, libraries such as OpenCL and CUDA were looked at. The final implementation uses pandas as the identification and management layer, the moviepy library as the processing backend, and CUDA as the GPU acceleration library, with some supplementary code employing regular expressions and system file handling to write the framebuffer contents to a file, as well as the json library to communicate with the rest of the server stack.
Goal and Summary: This suite of applications encompassed a way to manage, track and optimize inventory of the said product depending upon geographical areas with higher demand. This suite of applications included a dashboard for easy view and accountability by the management, and a field application to log sales, request inventory, and verify a sale with digital signature, fingerprint, as well as GPS tagging. Data Collected and Processed: The implementation began with an identification of the requirements of the organization. Accordingly, a Business Requirements Document was prepared, and a suitable track of development and deployment of this project was ascertained. The BRD included the projected user base of the application, estimated traffic on the applications, as well as the takeaways from the application to be used in other departments to propel product sales. Methodology: Keeping cognizance of the exigent nature of the need for implementation of this project owing to excessive sales bleed happening in the company, coupled with a lack of accountability of stock owing to supply chain issues, a no-code platform was selected to be the best route, since functionality and quick deployability superseded aesthetics in this case. There were two versions of the application designed: The initial production-level suite of 3 applications—one each for the field sales representatives, the management, as well as the channel partners—was developed and deployed on Google AppSheet for the best possible integration with the rest of the organization, which uses Google Cloud for its productivity. The design commenced on August 5th 2022, with a production test on the 23rd of August 2022. The second version of the suite was made in Microsoft Power Apps, with screens designed in Figma and Adobe Illustrator, owing to the organizational demand for enhanced UI/UX and the presently found bandwidth to improve these things. This was delivered less than 20 days later. Impact: The Company in question was able to regain accounts of their inventory, as well as ensure minimal bleed in terms of mismanaged, damaged or otherwise compromised stock. The average turnaround time for an end seller to have inventory delivered to them was reduced to intra-day, a departure from the existing weekly refresh cycle that was causative of returns.
This COVID-19 informational site was built to have a realtime view of the current COVID-19 cases in India. This website was built using the MERN stack, and over its lifetime, served more than 20,000+ visitors
When the Client wanted to implement data-driven automation for evaluation of an internal peer-to-peer learning and exchange program, a suite of applications were built using fundamental machine learning, as well as other allied libraries to handle data for 30+ Subject Matter Experts with a total user base of 1,200+ mentees. The data collected encompassed 40+ parameters, according to which a score would be assigned to the SME at the end of the learning period. These data points included weekly feedback from the mentees, as well as audit scores assigned internally by the QA team.
The Client’s demand was to collaborate with a government entity to establish the trend of air pollutants in Bangalore city. To accomplish this, there was put forth a demand of 50 AQM (air quality monitor) units to be deployed in various locations across the city. Proofs-of-concept and deployment-ready models were implemented using Honeywell HPMS series dust and air quality sensors in conjunction with GSM and GPS modules to provide a realtime dashboard of the air pollution trends across the city.
A patron walks in to a place- there’s a camera at the concierge to identify who he is. With a unique User ID associated with the scanned person, a hotel, for example, can immediately find bookings, provide analysis on cuisines or dishes that that person likes to order, the average spend to classify and compartmentalise into loyalty programmes, etc. Additionally, when the scanned person gets up to leave and the bill is paid, an alert can be sent to the valet to get the car out.
OVERVIEW:
Proactively detect anomalies as they occur on Companies external Managed Services Customer Network devices
Our ROAD MAP:
Research and development on different Machine Learning algorithms and finalise which will suit for hardware failure predictions. Analyse the data sources and process data for model building so that hardware failure model predicts ahead they occur.
CHALLENGES:
Predict and alert on potential outages prior to service interruption. Engineers can intervene and address the potential failures before they occur.
SOLUTIONS:
Developed a failure prediction model from network device syslogs that record events such as changes in interface states, configuration, power, line card connectivity etc..
RESULTS:
Performance degradation is avoided. Improved network & service availability. Imrpoved customer experience
OVERVIEW:
Aluminium 6061-T6 is a widely used alloy in various industries, including aerospace, automotive and marine due to its excellent combination of strength, corrosion resistance and formability. Its mechanical properties, particularly fatigue performance can be further improved through suitable processing techniques
CHALLENGES:
Despite the benefits of FSP on improving the fatigue properties of aluminum alloys, there are still some challenges that need to be addressed to optimize the process and achieve the desired results. Some of these challenges include - Process parameters, tool material, material characteristics, heat treatment and cost and time
SOLUTIONS:
Optimizing the FSP process parameters for improving the fatigue properties of Al 6061-T6 plates requires a comprehensive approach that considers the effect of process parameters on the microstructure and mechanical properties
of the material. By using a combination of experimental, computational, and analytical methods, it is possible to identify the optimal process parameters that lead to the desired properties.
Machine learning can used to optimize Friction Stir Processing (FSP) parameters for improving the fatigue properties of Al 6061-T6 plates. The use of machine learning algorithms can significantly reduce the time and cost of optimization by automating the process of parameter selection
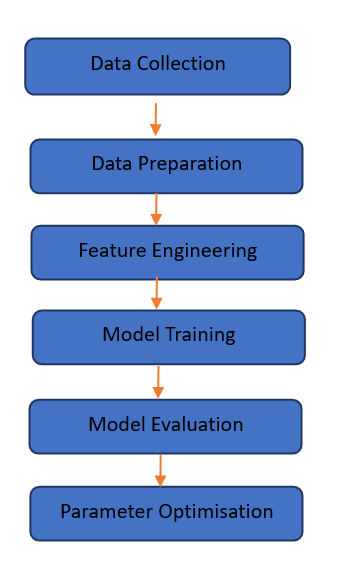 Data Collection: The first step is to collect data on the FSP process and the resulting fatigue properties of the material. This data can include process parameters such as tool rotation speed, traverse speed, and axial force, as well as the resulting fatigue strength of the processed material.
Data Preparation: The data must be cleaned and pre-processed before it can be used for machine learning. This involves removing any outliers, filling in missing values, and transforming the data into a suitable format for machine learning algorithms.
Feature Engineering: Feature engineering involves selecting the most relevant features or process parameters that are likely to have the most significant impact on the fatigue strength of the material.
Model Training: Machine learning algorithms can be used to build models that predict the fatigue strength of the material based on the selected process parameters. This involves selecting an appropriate algorithm (linear regression), splitting the data into training and validation sets, and tuning the hyperparameters of the model.
Model Evaluation: The trained model can be evaluated using various performance metrics such as root mean squared error (RMSE) and R-squared (R2) to determine its accuracy and reliability.
Parameter Optimization: The trained model can be used to predict the fatigue strength of the material for a wide range of parameter combinations. The model can then be used to identify the optimal combination of parameters that maximize the fatigue strength of the material.
.
Data Collection: The first step is to collect data on the FSP process and the resulting fatigue properties of the material. This data can include process parameters such as tool rotation speed, traverse speed, and axial force, as well as the resulting fatigue strength of the processed material.
Data Preparation: The data must be cleaned and pre-processed before it can be used for machine learning. This involves removing any outliers, filling in missing values, and transforming the data into a suitable format for machine learning algorithms.
Feature Engineering: Feature engineering involves selecting the most relevant features or process parameters that are likely to have the most significant impact on the fatigue strength of the material.
Model Training: Machine learning algorithms can be used to build models that predict the fatigue strength of the material based on the selected process parameters. This involves selecting an appropriate algorithm (linear regression), splitting the data into training and validation sets, and tuning the hyperparameters of the model.
Model Evaluation: The trained model can be evaluated using various performance metrics such as root mean squared error (RMSE) and R-squared (R2) to determine its accuracy and reliability.
Parameter Optimization: The trained model can be used to predict the fatigue strength of the material for a wide range of parameter combinations. The model can then be used to identify the optimal combination of parameters that maximize the fatigue strength of the material.
.
ROAD MAP:
One area of focus for future research is the development of deep learning models for predicting the fatigue strength of materials based on FSP parameters. Deep learning models are capable of processing large amounts of data and can identify complex patterns that may not be visible using other machine learning algorithms
RESULTS:
machine learning is a powerful tool for optimizing FSP parameters for improving the fatigue properties of Al 6061-T6 plates. By automating the process of parameter selection, machine learning can significantly reduce the time and cost of optimization while improving the accuracy and reliability of the results
The specific optimization method used and the target fatigue strength. However, in general, using machine learning can lead to significant improvements in the accuracy and efficiency of the optimization process.
Applied linear regression/support vector regression (SVR) algorithm to build a model that predicted the fatigue strength of the material based on the FSP process parameters
Feature variables are rotational speed, feed rate, tilt angle, no of pass and axial force
Target variable is ultimate tensile strength (UTS)
Model predict the UTS with an accuracy of 96.7%
OVERVIEW:
Potato Leaf Disease Prediction refers to the use of machine learning algorithms to predict the occurrence and severity of leaf diseases in potato plants. These diseases can have a significant impact on potato crop yields and quality, so predicting and identifying them early can help farmers take appropriate actions to mitigate their effects
There are various types of potato leaf diseases, including late blight, early blight, black dot, brown spot, and leaf roll virus. These diseases are caused by different pathogens and have distinct symptoms, such as yellowing or browning of leaves, lesions on leaves, and wilting of plants
potato leaf disease prediction is a promising application of machine learning in agriculture that has the potential to help farmers optimize their yields and improve their bottom line.
CHALLENGES :
potato leaf disease is the need to accurately predict and identify leaf diseases in potato plants early in their development to mitigate their impact on crop yield and quality
The challenge lies in developing accurate and effective methods for predicting and identifying potato leaf diseases
Traditional methods for disease identification rely on visual inspection by trained professionals, which can be time-consuming and subject to human error and the accuracy of visual inspection may be affected by factors such as lighting conditions and the experience of the inspector
SOLUTIONS:
Potato leaf disease prediction using Convolutional Neural Networks (CNN).
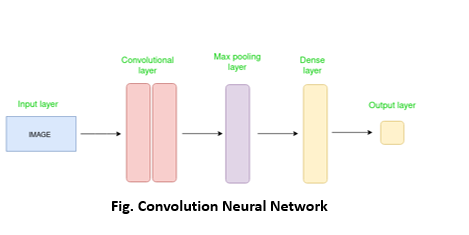 The CNN approach to potato leaf disease prediction involves using a deep learning algorithm that is specifically designed to analyze image data and identify patterns and features that are indicative of different types of leaf diseases in potato plants
Data collection: A large dataset of labeled images of potato leaves affected by different types of diseases (such as early blight, late blight, and leaf roll virus) and healthy leaves is collected.
Data pre-processing: The images are pre-processed by resizing, cropping, and normalizing them to make them suitable for input into the CNN model.
Model architecture: A CNN model is designed with multiple layers of convolutional, pooling, and fully connected layers to extract features from the input images and classify them into different types of diseases.
Model training: The model is trained on the pre-processed dataset using backpropagation and stochastic gradient descent optimization to minimize the loss function.
Model evaluation: The trained model is evaluated on a separate set of validation data to assess its accuracy in predicting the correct type of disease.
Model deployment: The trained CNN model is deployed in the field by farmers who can capture images of potato leaves using a smartphone or other digital camera and feed them into the model for analysis. The model then predicts the type of disease affecting the leaves, along with a confidence score.
The CNN approach to potato leaf disease prediction involves using a deep learning algorithm that is specifically designed to analyze image data and identify patterns and features that are indicative of different types of leaf diseases in potato plants
Data collection: A large dataset of labeled images of potato leaves affected by different types of diseases (such as early blight, late blight, and leaf roll virus) and healthy leaves is collected.
Data pre-processing: The images are pre-processed by resizing, cropping, and normalizing them to make them suitable for input into the CNN model.
Model architecture: A CNN model is designed with multiple layers of convolutional, pooling, and fully connected layers to extract features from the input images and classify them into different types of diseases.
Model training: The model is trained on the pre-processed dataset using backpropagation and stochastic gradient descent optimization to minimize the loss function.
Model evaluation: The trained model is evaluated on a separate set of validation data to assess its accuracy in predicting the correct type of disease.
Model deployment: The trained CNN model is deployed in the field by farmers who can capture images of potato leaves using a smartphone or other digital camera and feed them into the model for analysis. The model then predicts the type of disease affecting the leaves, along with a confidence score.
Road Map:
Different leaf disease prediction such as Grapes/Cashew involves selecting relevant features from the input images that can help distinguish healthy leaves from those affected by different types of diseases.
Here are some common features used in leaf disease prediction includes-
RESULTS:
The result of potato leaf disease prediction using CNN can vary depending on various factors such as the quality and quantity of the dataset, the architecture of the CNN model, the pre-processing of input images, and the evaluation metrics used to assess the performance of the model
The performance of the CNN model is evaluated using metrics such as accuracy, precision, recall, and F1 score
Model predict the potato leaf disease/normal with the accuracy of 95%.
BUSINESS OUTCOME
• Early detection and diagnosis
• Improved crop yields
• Reduced use of pesticides
• Cost saving
• Increase food security
Framework Used: TensorFlow and Keras
Language Used: Python
Hardware Used: T4-GPU
Crezam
Problem Statement: Creative Market is unorganized with respect to job opportunities for creators. There was a need to build an ecosystem platform which connects creators & design agencies
Solution: A mobile application for creators on Flutter (front end), Java full stack (backend) using microservices has been developed. Also, an ERP web application for design agencies on Java full stack
Global Airlines company
Problem Statement: ERP from on-premise SAGE to Microsoft Dynamics 365 on Azure
Solution: End to end project implementation & post Go-Live support & training to Abu Dhabi & Mauritania
Aruba Wireless Networks
Problem Statement:The company had very specific issues in parking which effected the security, employee productivity, resource utilization & information availability
Solution: IoT solution leveraging Aruba Wi-Fi. Solution used RFID in the gates & BLE tages for the cars to allocate zones in the parking lot
Norsk Hydro ASA
Problem Statement:Food wastage as employees come in different shifts & no real time visibility on number of people having lunch, tea or dinner
Solution: Custom built web application for canteen management which shall print specific tokens based on them IN Time
Triveni Turbine Ltd
Problem Statement:They faced problem in getting the video testimonial of their international clients as they have to rely on professionals to travel to their factory from Bangalore, which took lot of time in co-ordination & affected the customer satisfaction rating
Solution: Custom built android application & video testimonial room setup
HM towers
Problem Statement:Security at individual blocks & tracking of visitors
Solution: Custom built web application on visitor management